We present TartanGround, a large-scale, multi-modal dataset to advance the perception and autonomy of ground robots operating in diverse
environments. This dataset, collected in various photorealistic simulation environments includes multiple RGB stereo cameras for 360-degree
coverage, along with depth, optical flow, stereo disparity, LiDAR point clouds, ground truth poses, semantic segmented images, and occupancy
maps with semantic labels. Data is collected using an integrated automatic pipeline, which generates trajectories mimicking the motion
patterns of various ground robot platforms, including wheeled and legged robots. We collect 878 trajectories across 63 environments,
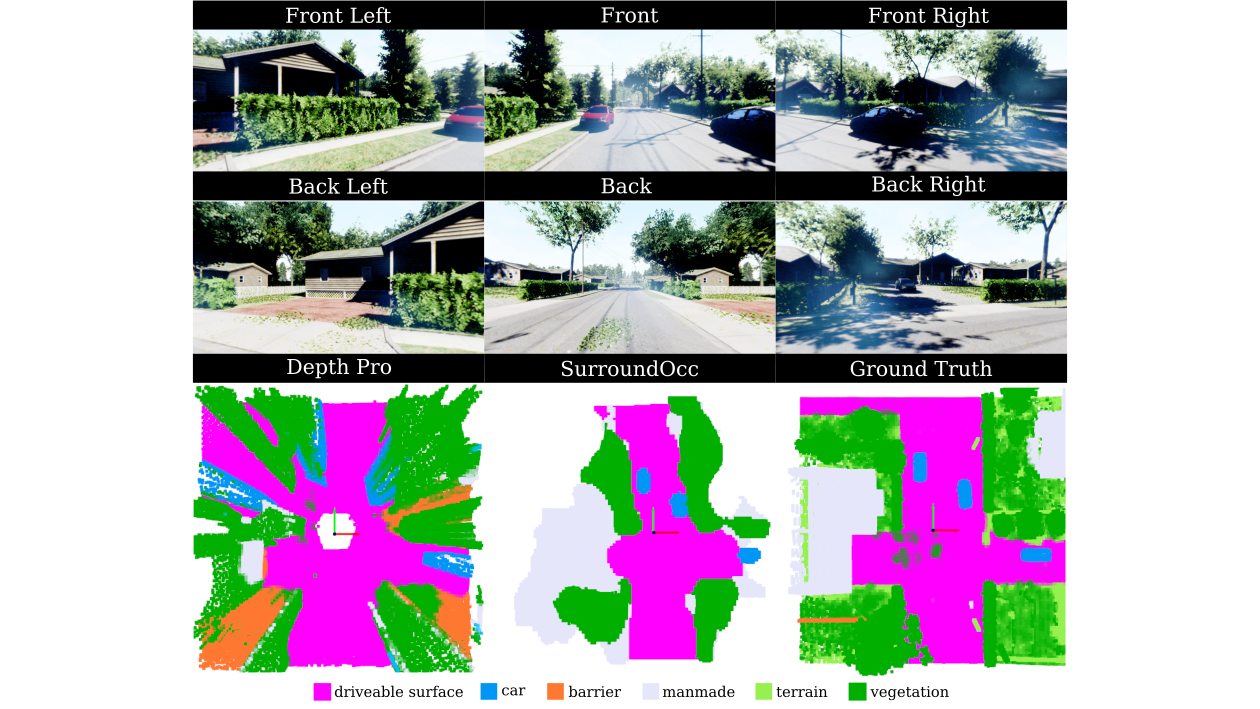
resulting in 1.44 million samples. Evaluations on occupancy prediction and SLAM tasks reveal that state-of-the-art methods trained on
existing datasets struggle to generalize across diverse scenes. TartanGround can serve as a testbed for training and evaluation of a broad
range of learning-based tasks, including occupancy prediction, SLAM, neural scene representation, perception-based navigation, and more,
enabling advancements in robotic perception and autonomy towards achieving robust models generalizable to more diverse scenarios.